
前段时间,与客户交流项目需求,其中涉及到数据库的同步,源数据库为阿里云RDS,使用的是MySQL5.7。具体需求是要同步阿里云RDS库的部分表,还需要对表的列做过滤,比如某些列column由于业务敏感不做同步,并且根据列column的字段信息,对行row进行where过滤,比如根据租户id过滤后同步数据。
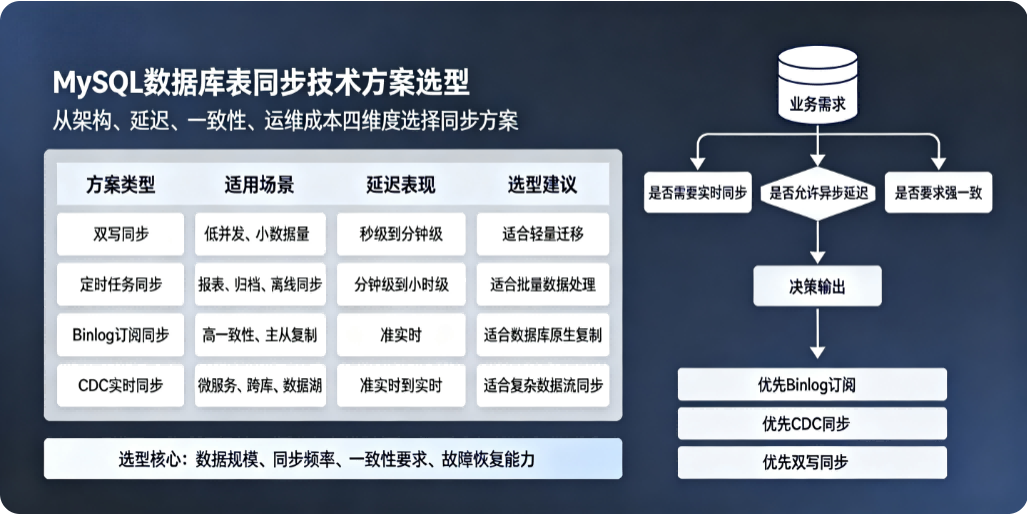
综合分析比较,列出如下主流的技术方案,各位也可以根据自己项目的使用场景与实时性要求进行选择。
1. 轻量 / 简单方案(适合小表、非实时)
①mysqldump + 定时导入
适用:少量表、非实时同步、测试环境
原理:定时导出指定表 → 导入到目标库
优点:简单、无额外组件
缺点:非实时、有锁、大表慢
②SELECT ... INTO OUTFILE / LOAD DATA
适用:定期全量同步部分表
优点:比 mysqldump 快
缺点:仍非实时,需要文件权限
③应用层双写 / 消息队列(MQ)
适用:能改业务代码、需要精确控制同步逻辑
方案:
写主库同时发 MQ(Kafka/RabbitMQ)
消费端写入从库指定表
优点:灵活、只同步关心的表 / 字段
缺点:侵入业务,需保证消息不丢不重
2. 准实时同步
①Canal(阿里开源,最常用)
原理:伪装成 MySQL slave,解析 binlog,只同步指定表
优点:
只同步部分库 / 表 / 字段
实时、低延迟
支持过滤、转换、异构目标
典型栈:Canal + Canal Admin + Kafka + 自定义消费者
②Debezium(基于 Kafka Connect)
原理:CDC捕获 binlog,输出到 Kafka
优点:生态强、支持多数据库,精确表 / 行过滤
适合:大数据平台、ETL 场景
③DTS / 云厂商同步工具
阿里云DTS、腾讯云 DTS、AWS DMS
优点:开箱即用、支持部分表同步、监控完善
缺点:付费、受云厂商绑定
3. MySQL 原生方案
①主从复制 + 复制过滤
优点:原生稳定、延迟低
缺点:过滤规则容易踩坑(跨库语句问题),不支持字段级过滤,不适合异构库、数据转换
②MySQL 8.0 Clone / 克隆 + 增量
适合:首次全量 + 后续 binlog 增量,只做部分表不太方便
4.ETL 工具(适合复杂清洗转换)
①DataX / Flinkx / Sqoop
定时同步部分表,支持增量(按时间 / 主键)
优点:强大的字段映射、清洗、分批
缺点:一般是准实时 / 定时,不是秒级实时
②. Flink / Spark Streaming
适合:复杂实时计算后再写入目标库
缺点:方案较重,开发成本高
原文链接
欢迎访问 小易撩挨踢