
2026 年,大模型早已不是 "要不要做" 的选择题,而是 "怎么做才能不踩坑、真落地" 的必答题。
太多企业陷入了同一个误区:盲目追逐千亿参数、跟风最新模型,投入百万算力却只做出一个 "会聊天的机器人";要么技术选型混乱,今天换框架明天换基座,最终变成烂尾工程;要么贪多求全,一上来就想做全栈通用大模型,结果连最基础的知识库问答都做不好。
大模型落地的核心从来不是 "技术有多新",而是 "节奏有多准"。什么时候用 7B 模型,什么时候升级 MoE?先做 RAG 还是先做 Agent?哪些技术是必选,哪些只是噱头?
这篇文章为你整理了大模型落地三年完整作战图,从 0-12 个月快速上手,到 12-24 个月深度业务绑定,再到 24-36 个月战略卡位,明确标注每个阶段的核心目标、必选技术栈、工具链组合、落地场景和风险应对。没有空谈趋势,只有可直接复制的执行方案。
前言摘要
本文基于 2026 年大模型技术发展现状与产业落地实践,提出了0-36 个月分阶段落地路线图,为企业从 0 到 1 搭建 AI 能力提供可执行的技术指南。
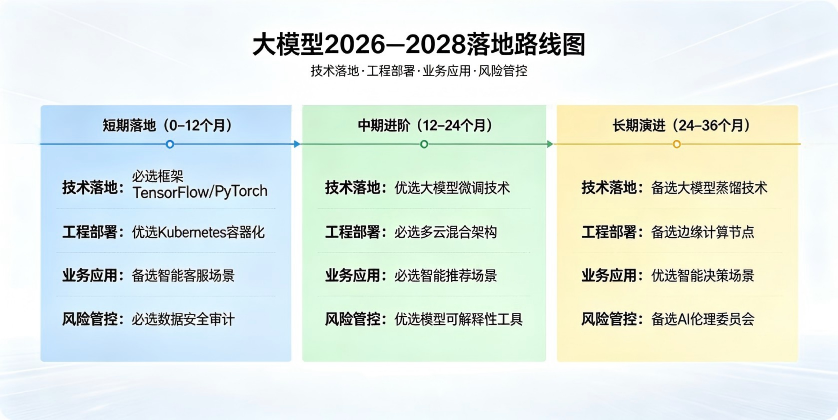
将大模型落地分为三个核心阶段:短期(0-12 个月)聚焦快速可用,推荐采用 Qwen3/Llama 3 等 7B/13B 开源基座,通过 LoRA/QLoRA 轻量化微调与 vLLM 推理优化,快速落地知识库问答、办公助手等基础场景;中期(12-24 个月)聚焦能力升级,引入 MoE 混合专家模型、原生多模态与复杂 Agent 技术,搭建分布式训练集群,深度绑定金融、法律、工业等垂直业务;长期(24-36 个月)聚焦战略布局,预研神经符号融合、世界模型与可信 AI 技术,构建自主可控的全栈大模型体系。
提供了详细的技术选型对比、工具链组合方案与风险应对策略,帮助企业避开技术陷阱,以最小投入实现最大产出,在大模型产业革命中抢占先机。整体分为短期落地(0–12 个月)、中期进阶(12–24 个月)、长期演进(24–36 个月),兼顾技术落地、工程部署、业务应用与风险管控,同时标注必选 / 优选 / 备选技术与框架。

一、第一阶段:短期落地(0–12 个月,优先级:最高)
核心目标
快速搭建可用底座,完成通用模型部署、轻量化微调、基础 RAG / 简单 Agent落地,控制成本、保障稳定性,适配现有硬件。
1. 核心技术选型(必选)
2. 工具链组合(直接复用)
模型加载 / 管理:Hugging Face Transformers + Accelerate
微调框架:LLaMA-Factory / Unsloth(二选一)
追求极致速度:Unsloth
追求功能全面、多模型兼容:LLaMA-Factory
推理服务:vLLM(生产首选),本地测试可用 llama.cpp
RAG 开发:LlamaIndex / LangChain
硬件适配:优先 NVIDIA GPU;国产卡选用框架原生适配版本
3. 落地场景(优先落地)
企业知识库问答、文档摘要、内部客服
简单办公助手:文案生成、格式整理、代码辅助
垂直轻量化微调:行业话术、专属指令适配
4. 关键风险 & 应对
量化后效果下滑:分层量化,关键层保留 8-bit,通用层用 4-bit
RAG 检索不准:优化文档分块、嵌入模型选型、重排序(Rerank)
并发吞吐不足:开启连续批处理、限制单轮上下文长度
数据合规:内部数据脱敏,禁止上传涉密 / 隐私数据
二、第二阶段:中期进阶(12–24 个月,优先级:高)
核心目标
升级架构与能力,落地MoE 模型、原生多模态、复杂 Agent、端云协同,搭建企业级分布式训练 / 推理集群,深度绑定垂直业务。
1. 核心技术选型(优选)
2. 工具链补充
分布式训练:DeepSpeed(上手简单)/ Megatron-LM(大规模预训练)
多模态开发:统一使用 Transformers 生态多模态模型库
Agent 工程化:LangChain + 自研记忆 / 调度模块
端侧部署:llama.cpp、移动端推理 SDK,实现手机 / 边缘设备离线运行
3. 落地场景(深度落地)
行业专属大模型:金融、法律、工业、医疗领域定制模型
复杂自动化流程:数字员工、合同全流程审核、运维智能巡检、科研辅助
多模态业务:图文分析、视频内容理解、工业视觉 + 文本联动
端云协同方案:云端做大模型推理 / 训练,边缘端轻量化模型负责隐私侧交互
4. 关键风险 & 应对
MoE 路由不均、负载失衡:优化路由算法,做专家负载监控与调度
分布式集群通信瓶颈:升级网络架构,启用 Ring AllReduce、通信优化
多模态对齐差、跨模态出错:补充领域多模态训练数据,加强跨模态对齐
端侧性能不足:模型蒸馏、极致量化(2-bit)、模型裁剪
三、第三阶段:长期演进(24–36 个月,优先级:战略布局)
核心目标
布局下一代架构、世界模型、神经符号融合、可信 AI、专用算力,构建自主可控的全栈大模型体系,探索前沿商业化形态。
1. 核心技术选型(布局 / 预研)
2. 工具链 & 生态布局
自研部分核心算子、推理内核,降低对外开源框架依赖
搭建数据生产、模型训练、评测、安全审计全流程自研平台
参与行业标准制定,对接国产软硬件生态
3. 落地场景(前沿探索)
工业数字孪生、机器人智能控制、复杂科学计算
全自主数字员工、全域智能运维、全域知识大脑
面向 C 端的离线端侧超级 AI、沉浸式多模态交互
4. 关键风险 & 应对
前沿技术落地慢、投入产出比低:小团队预研 + 试点验证,不盲目大规模投入
技术壁垒与人才缺口:组建专项技术团队,产学研合作
安全与伦理风险:建立全流程安全审计、内容风控、行为约束体系
生态兼容问题:提前适配国产软硬件,完成信创适配改造
四、整体优先级 & 资源投入建议
0–12 个月(当下重点)
资源倾斜:工程部署、数据治理、基础 RAG / 微调
原则:先能用、再好用,不追逐前沿花哨技术
12–24 个月(能力升级)
资源倾斜:分布式集群、MoE、多模态、Agent 工程化
原则:降本增效 + 业务深度绑定,形成差异化竞争力
24–36 个月(战略布局)
资源倾斜:前沿预研、算力自研、可信体系、生态建设
原则:技术卡位,布局未来 3 年核心竞争力
五、精简版技术选型速查
入门 / 本地测试:Llama 3/Qwen3 + llama.cpp + LoRA
企业生产推理:vLLM / SGLang + AWQ/FP8 量化
批量微调:LLaMA-Factory / Unsloth + DPO
大规模训练:DeepSpeed + MoE 架构
RAG 应用:LlamaIndex + LangChain
复杂 Agent:LangChain + 记忆 / 反思模块
端侧离线:llama.cpp + 极致量化
欢迎访问 小易撩挨踢